기획부터 출시까지의 탐슬 도감 여정
2025-10-12
원본링크: https://velog.io/@wngns9807/%EA%B8%B0%ED%9A%8D%EB%B6%80%ED%84%B0-%EC%B6%9C%EC%8B%9C%EA%B9%8C%EC%A7%80%EC%9D%98-%ED%83%90%EC%8A%AC-%EB%8F%84%EA%B0%90-%EC%97%AC%EC%A0%95
프로젝트 소개
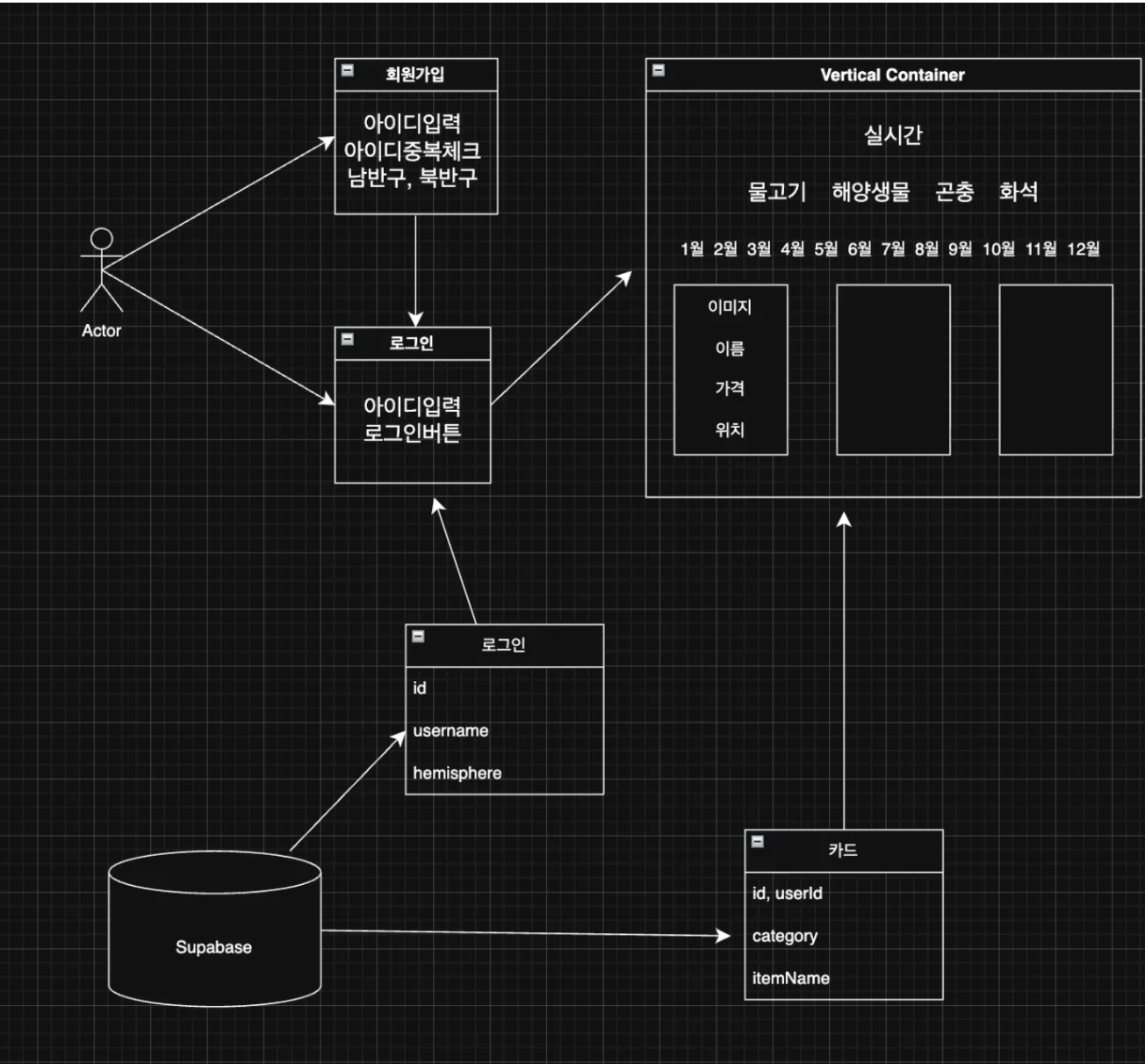
탐슬도감은 모여봐요 동물의 숲 플레이어를 위한 도감 정리 웹앱이다. 이름·월·시간·반구 필터를 한 번에 적용하고, 잡은 항목을 관리할 수 있는 도구로, 10월의 어느 주말 하루 만에 탄생했다.
시작: "이거 만들어줄 수 있어?"
모동숲을 하던 지인이 불편함을 토로했다.
"기존 도감 앱들은 광고가 너무 많아. 광고 없애려면 돈 내야 하고, 그것도 좀 그래서..."
이야기를 듣다 보니 불편한 점이 한두 가지가 아니었다.
- API가 영어로 되어 있어서 모든 이름이 영어로 표시됨 (한국 사용자에게 불편)
- 잡은 것과 안 잡은 것을 표시하는 기능이 부족함
- 월별·시간별로 필터링이 안 되거나 불편함
- 잡히는 위치 정보가 명확하지 않음
"그럼 내가 한번 만들어볼까?"
가볍게 시작한 말이었지만, 막상 시작하니 생각보다 재밌을 것 같았다. 그동안 프론트엔드만 하면서 느꼈던 한계를 넘어, 풀스택으로 첫 도전을 해보고 싶었던 참이었다.
개발: AI와 함께한 10시간의 코딩
10월의 어느 주말, 아침 일찍 자리에 앉았다.
"오늘 하루 안에 끝내자."
그동안 프론트엔드만 해왔던 나에게 백엔드는 미지의 영역이었다. 하지만 Supabase와 Drizzle ORM을 선택하면서 조금은 자신감이 생겼다. 그리고 AI와 함께하는 바이브 코딩으로 막히는 부분을 빠르게 해결해나갔다.

첫 번째 도전: 풀스택으로의 첫걸음
프론트엔드만 하던 내가 백엔드까지 직접 구현한다는 건 쉽지 않은 도전이었다.
- 데이터베이스 설계는 어떻게 해야 할까?
- API는 어떻게 만들어야 할까?
- 사용자 데이터는 어떻게 저장하고 관리해야 할까?
Supabase를 선택한 건 정말 잘한 선택이었다. 인증, 데이터베이스, API까지 모두 제공되어 백엔드 인프라를 빠르게 구축할 수 있었다. Drizzle ORM으로 타입 안전한 쿼리를 작성하면서, "아, 이게 풀스택이구나"라는 느낌이 들었다.
두 번째 도전: 데이터 최적화
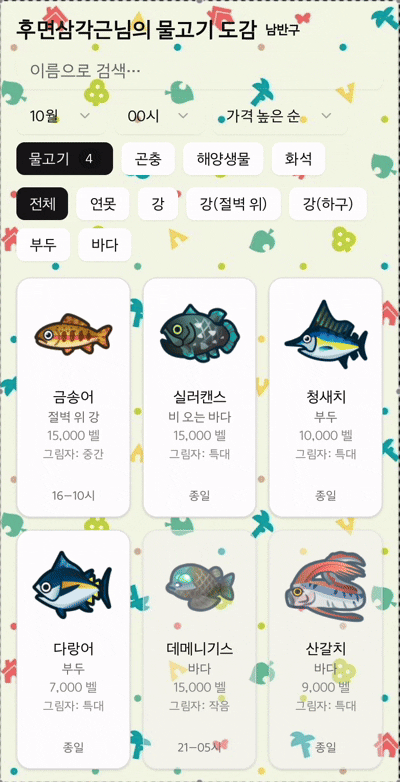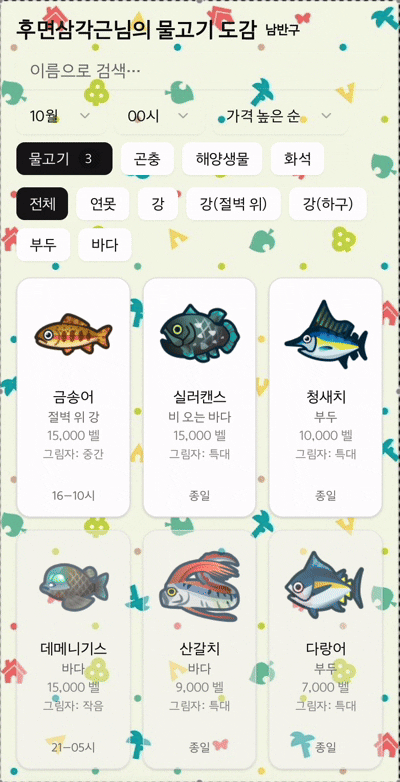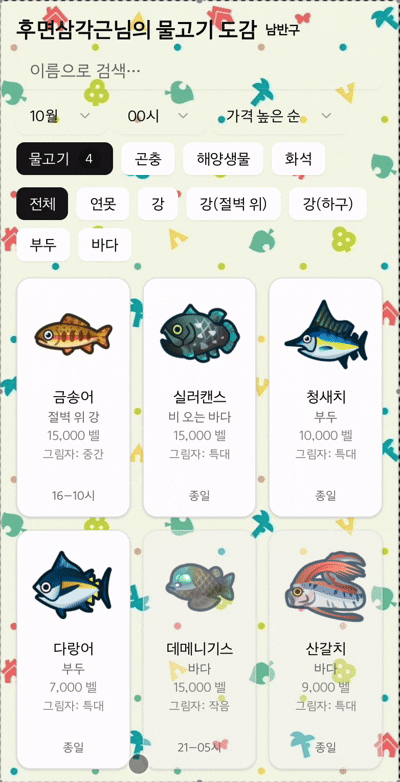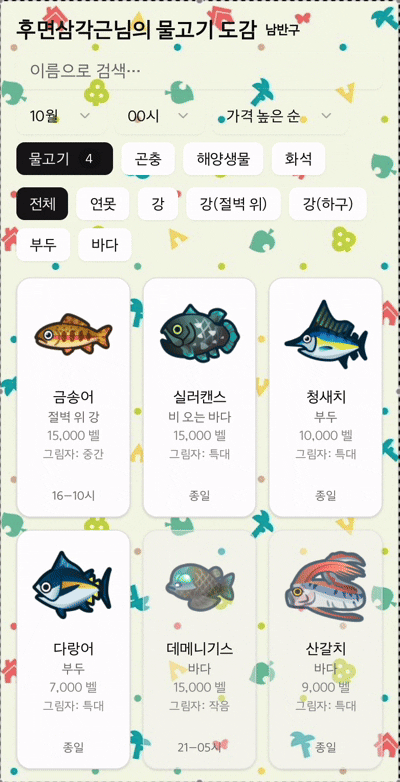
모동숲의 물고기, 곤충, 해양생물, 화석을 합치면 총 500개가 넘는 항목이 있었다. 처음엔 "그냥 다 보내면 되지 않을까?"라고 생각했지만, 모바일에서 사용할 사용자를 생각하니 데이터 사용량이 걱정되었다.
특히 사용자가 "3월에 잡을 수 있는 물고기"만 보고 싶은데, 12개월치 데이터를 모두 받아서 클라이언트에서 필터링하는 건 명백한 낭비였다.
고민 끝에 서버측 필터링을 도입했다. API에 month와 only 파라미터를 추가해, 서버에서 먼저 해당 월에 출현하는 항목만 필터링하도록 했다. Drizzle ORM의 복잡한 쿼리 조건을 활용해 데이터베이스 레벨에서 필터링이 이루어지도록 구성했다.
// 서버측 필터링 적용
const filtered = only && month >= 1 && month <= 12
? normalized.filter((it) =>
(hemi === "north" ? it.north.months_array : it.south.months_array).includes(month)
)
: normalized;
결과는 놀라웠다. 전송 데이터 크기가 평균 70% 이상 감소했고, 특히 월별 필터를 사용하는 경우 로딩 시간이 눈에 띄게 줄어들었다.
세 번째 도전: 한글 친화적인 검색
기존 앱들은 API가 영어로 되어 있어서 모든 이름이 영어로 표시되었다. 한국 사용자들이 "참치"를 검색하면 "tuna"를 찾을 수 있어야 했다.
서버에 한글 매핑 테이블을 미리 구축하고, 데이터베이스에 저장할 때 영어 이름과 한글 이름을 함께 저장했다. 클라이언트에서는 단순 문자열 매칭만 하면 되도록 설계했다.
// 서버에서 한글 이름 매핑
const nameKo = it.nameKo || nameKoMap[it.originalName] || it.originalName;
// 클라이언트에서 한글/영어 모두 검색
const matchesQuery = (it: Item, q: string) => {
if (!q) return true;
const needle = q.trim().toLocaleLowerCase("ko-KR");
const hay = [it.name, it.originalName].join(" ").toLocaleLowerCase("ko-KR");
return hay.includes(needle);
};
네 번째 도전: 즉각 반응하는 체크 UX
잡은 항목을 체크하는 기능은 탐슬도감의 핵심이었다. 처음에는 서버 요청을 보내고 응답을 받은 뒤에 UI를 업데이트했는데, 네트워크 지연이 있을 때 사용자가 "응답이 없는 건가?" 하고 다시 클릭하는 문제가 발생했다.
낙관적 업데이트 패턴을 적용했다. 사용자가 카드를 클릭하는 순간 즉시 UI를 업데이트하고, 백그라운드에서 서버 요청을 처리했다. 만약 서버 요청이 실패하면 변경사항을 롤백하는 방식이었다.
// 낙관적 업데이트 구현
const toggleCatch = useCallback(async (itemName: string) => {
// 즉시 UI 업데이트
setCaughtSet((prev) => {
const next = new Set(prev);
if (next.has(itemName)) next.delete(itemName);
else next.add(itemName);
return next;
});
try {
const res = await fetch("/api/caught/toggle", { /* ... */ });
const data = await assertJson<{ caught: boolean }>(res);
setCaughtSet((prev) => {
const next = new Set(prev);
if (data.caught) next.add(itemName);
else next.delete(itemName);
return next;
});
} catch (e) {
// 실패 시 롤백
setCaughtSet((prev) => {
const next = new Set(prev);
if (next.has(itemName)) next.delete(itemName);
else next.add(itemName);
return next;
});
}
}, [userId, category]);
사용자가 체크하는 즉시 반응하는 느낌을 줄 수 있었다. 네트워크가 느려도 UI는 바로바로 반응했고, 사용자 경험이 크게 개선되었다.
출시: 디시에서 시작된 작은 반향
10시간의 코딩 끝에, 드디어 탐슬도감을 출시할 수 있었다.
"어디에 공유하지?"
고민 끝에 디시 모여봐요 동물의 숲 갤러리에 글을 올렸다. 기대 반 걱정 반이었다.
"무료로 편하게 이용해주세요..!"
반응은 예상보다 훨씬 뜨거웠다.
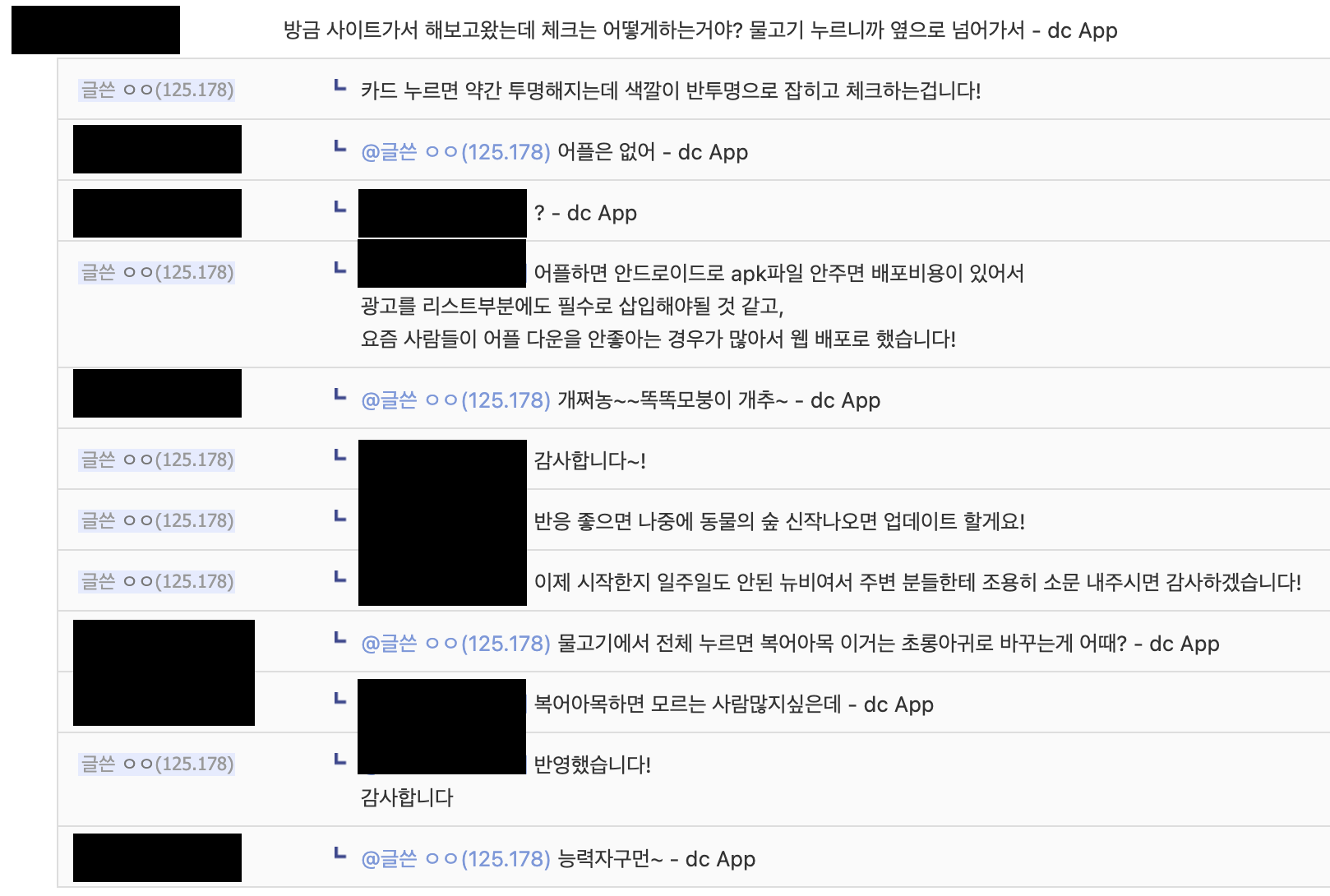
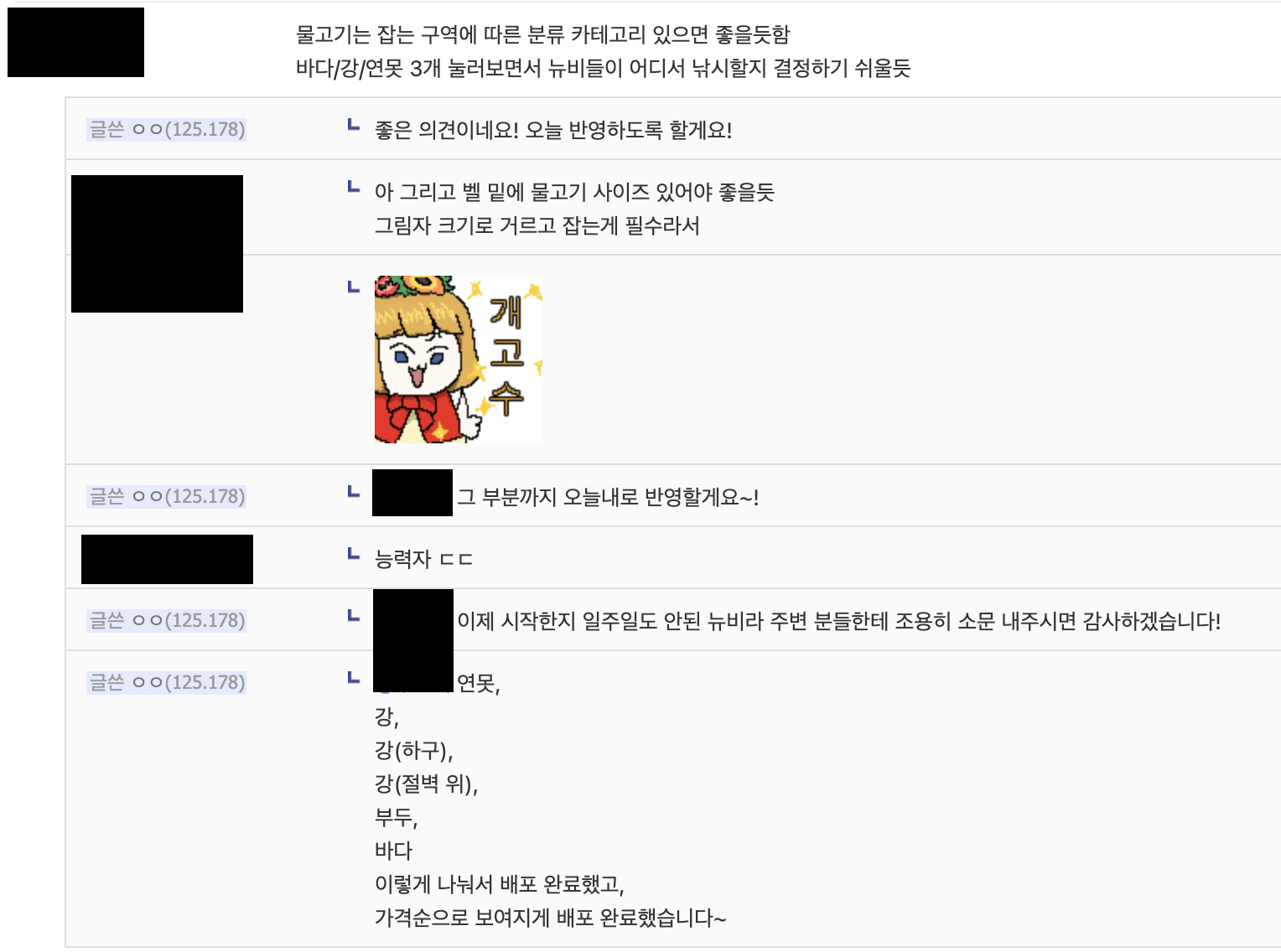
첫 주에만 40명의 사용자가 생겼고, 그 이후로도 주당 10명씩 꾸준히 늘어나고 있다. 현재는 약 60명의 사용자가 탐슬도감을 이용 중이다.
혼자서 만든 작은 프로젝트가 이렇게 많은 사람들에게 도움이 된다는 게 신기하면서도 뿌듯했다.
마무리하며: 풀스택으로의 첫걸음
하루 만에 만든 프로젝트지만, 배운 것은 정말 많았다.
프론트엔드만 하던 내가 처음으로 백엔드까지 직접 구현하면서, "이게 풀스택이구나"라는 걸 몸소 느꼈다. 데이터베이스 설계부터 API 구현, 클라이언트 최적화까지 모든 과정을 직접 경험하면서, 서비스를 만드는 전체 흐름을 이해할 수 있었다.
특히 서버측 필터링으로 데이터 전송량을 70% 줄이고, 낙관적 업데이트로 사용자 경험을 개선하고, 한글 친화적인 검색을 구현하면서, 사용자가 원하는 것을 어떻게 효율적으로 제공할 수 있을지 고민하는 과정 자체가 즐거웠다.
그리고 무엇보다, 지인의 불편함을 해결해주려고 시작한 작은 프로젝트가 60명의 사용자에게 도움이 되고 있다는 사실이 가장 큰 보람이다.
프론트엔드 개발자로서의 관점 변화
이 프로젝트를 통해 프론트엔드 개발자로서 내가 가진 강점이 무엇인지 명확히 깨달았다.
예전에는 "사용자의 반응을 가장 가까이서 볼 수 있다"는 점이 좋아서 프론트엔드를 선택했다면, 이제는 그 관점이 더 확장되었다. 프론트엔드 개발자는 사용자가 버튼을 클릭하고, 데이터를 입력하고, 화면을 보는 그 순간을 직접 목격한다. 그래서 "무엇이 진짜 필요한지"를 가장 먼저, 가장 정확하게 파악할 수 있다.
백엔드 개발자도 필요한 API를 만들 수 있지만, 그건 대부분 요구사항이나 추측을 기반으로 한다. 반면 프론트엔드 개발자는 사용자의 실제 행동을 보면서 "아, 여기서 이 데이터가 필요하구나"를 체감한다. 이 차이가 크다.
그리고 이제 풀스택 역량까지 갖추게 되면서, 사용자 친화적인 관점으로 발견한 필요를 처음부터 끝까지 혼자서 구현할 수 있게 되었다. API를 활용해서 필요한 것을 바로 만들 수 있고, 그 과정에서 항상 사용자를 최우선으로 고려할 수 있다는 점. 이게 프론트엔드 개발자가 풀스택으로 확장되었을 때 가진 진짜 강점이라고 생각한다.
프론트엔드 개발자로서 항상 느꼈던 한계를 넘어, 이제는 풀스택으로 서비스를 만들 수 있다는 자신감을 얻었다. 그리고 그 중심에는 여전히 "사용자"가 있다.